Claude ouvre son contexte à 1 million de tokens : ce que ça change vraiment

La fenêtre grand ouverte — Bonne nouvelle pour les utilisateurs de Claude Code et les développeurs qui vivent dans les 200K tokens depuis trop longtemps : Anthropic rend disponible le contexte d'un million de tokens pour Opus 4.6 et Sonnet 4.6, à tarification standard.
Fini le multiplicateur de prix pour les longs contextes, fini aussi les compactions qui surgissaient, il faut l'avouer, au pire moment.
Pour ceux qui ont passé des heures à regarder Claude "oublier" une décision prise 150 000 tokens plus tôt, l'annonce d'Anthropic devrait impliquer un changement concret dans le raisonnement de sa solution.
Ce qui change vraiment
La compaction, c'est l'ennemi du développeur qui travaille en session longue avec Claude Code.
Vous êtes en plein milieu d'une investigation complexe, vous avez remonté une chaîne de bugs à travers cinq fichiers, et... BIM. Compaction en cours. Et là, on prie un peu pour que le résumé automatique généré ait surtout retenu l'essentiel (spoiler : c'est assez rare).
Avec 1 million de tokens, ces interruptions deviennent beaucoup moins fréquentes. Pour Claude Code, les utilisateurs Max, Team et Enterprise sur Opus 4.6 basculent désormais sur la fenêtre complète par défaut.
Concrètement : une codebase entière, des logs volumineux, ou la trace complète d'un agent long-running (appels d'outils, observations, raisonnements intermédiaires...) peuvent tenir dans un seul et unique contexte, sans avoir à jongler entre différentes conversations.
La limite média monte également à 600 images ou pages PDF par session. Pour les workflows qui manipulent de la documentation technique dense, ça change carrément la donne.
Est-ce que ça tient à cette échelle ?
C'est là que ça devient intéressant, et la réponse n'est pas binaire. Anthropic cite un score de 78,3% sur le benchmark MRCR v2 pour Opus 4.6 à 1M de tokens, ce qu'ils présentent comme le meilleur résultat parmi les modèles frontier à cette longueur de contexte.
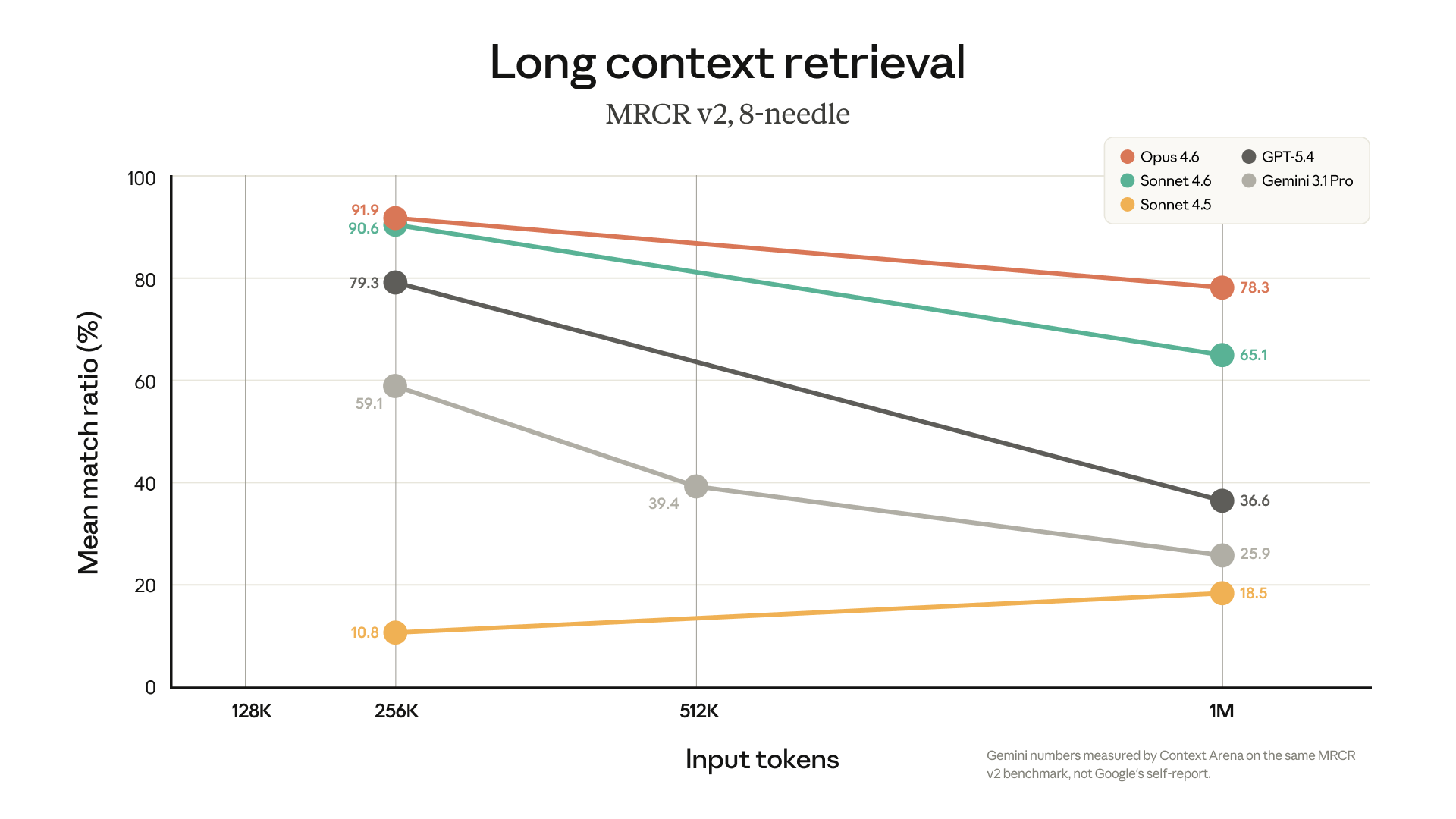
Les développeurs qui testent le modèle en conditions réelles font quant à eux état d'une dégradation qui commencerait aux alentours des 600-700K tokens : instructions oubliées, décisions prises en début de session qui ne persistent pas jusqu'à la fin.
On n'est pas encore sur du contexte infini "magique" : c'est un espace de travail beaucoup plus grand, certes, mais qui continue à souffrir des mêmes limitations fondamentales d'attention.
La discipline qui semble émerger chez les power users : rester sous les 100-150K tokens pour le travail quotidien, et réserver la pleine fenêtre aux cas où c'est vraiment nécessaire, comme des grosses analyses d'un monorepo entier, le débogage d'un agent long-running, ou encore l'ingestion d'une documentation volumineuse.
Pour les équipes qui buildent des agents sur l'API, la fenêtre élargie pose une question d'architecture. Plus de contexte disponible, c'est mécaniquement plus de tokens consommés par session, et la facture suit.
La question du routage devient alors critique : quelles tâches nécessitent vraiment Opus à 1M, et lesquelles peuvent tourner sur Sonnet à 200K ? La bonne réponse, c'est probablement 80% du temps la deuxième option.
Le vrai gain, au fond
Le contexte à 1 million de tokens ne va pas résoudre les limitations fondamentales d'attention des LLMs. En revanche, il va drastiquement réduire les compactions qui surgissent au pire moment et détruisent un contexte qu'on a mis deux heures à construire.
Pour les agents long-running, les sessions de refactoring profond, et les investigations qui se baladent dans des dizaines de fichiers : c'est un vrai gain de confort au quotidien. Pas la solution miracle, mais un vrai upgrade.
À propos de l'auteur

Nicolas Lecointre
Chief Happiness Officer des développeurs, ceinture noire de sudo. Pour rire, j'ai créé Les Joies du Code. J'utilise Vim depuis 10 ans parce que je sais pas comment le quitter.
À lire également

Ma phobie administrative a enfin trouvé son fix, et il s’appelle Abby
Je DÉTESTE, je HAIS l'administratif. Voilà, c'est dit, et ça me semble être une belle entrée en matière pour cet article. C’est assez simple, à mon niveau, tout ce qui...
Articles similaires

Anthropic lance un outil IA de code review pour traquer les bugs dans vos pull requests
TurboQuant : Google réussit à diviser la mémoire de l'IA par 6, sans perdre en précision

Ollama passe à MLX : l'IA locale sur Mac passe la seconde

Anthropic laisse fuiter 512 000 lignes de Claude Code sur npm
Anthropic lance un outil IA de code review pour traquer les bugs dans vos pull requests
TurboQuant : Google réussit à diviser la mémoire de l'IA par 6, sans perdre en précision
Ollama passe à MLX : l'IA locale sur Mac passe la seconde
Anthropic laisse fuiter 512 000 lignes de Claude Code sur npm
Plus de contenu

Quand je vois la liste de toutes les fonctionnalités que je dois livrer avant la fin du mois

Quand je suis les instructions pour reproduire un bug exotique

Quand je découvre le lundi matin que la prod est tombée pendant le week-end

Quand j'embarque sur un nouveau projet et qu'on me demande de monter l'environnement

Quand je me lance sur une grosse refactorisation

Quand on démarre un nouveau projet avec le binôme

Quand je suis sur le point d'expliquer aux collègues comment j'ai corrigé un bug bloquant

Quand j'entends parler d'une mise en prod pour vendredi
Quand je vois la liste de toutes les fonctionnalités que je dois livrer avant la fin du mois
Quand je suis les instructions pour reproduire un bug exotique
Quand je découvre le lundi matin que la prod est tombée pendant le week-end
Quand j'embarque sur un nouveau projet et qu'on me demande de monter l'environnement
Quand je me lance sur une grosse refactorisation