Meta soupçonné d'avoir triché pour faire briller son nouveau modèle Llama 4 dans les benchmarks d'IA

La main dans le sac ? — Le lancement de la famille de nouveaux modèles IA Llama 4 par Meta ce week-end n'a pas manqué de faire du bruit dans les sphères tech.
Présentés comme des poids lourds de l'intelligence artificielle, les modèles Scout et Maverick de la famille Llama 4 ont été annoncés comme les premiers à intégrer l’approche Mixture of Experts (MoE) — une technique d'architecture qui permet d’augmenter la puissance d’un modèle tout en limitant les ressources utilisées à chaque requête.
Mais au-delà des performances techniques affichées, une controverse a rapidement éclaté : Meta aurait soumis une version non publique de Llama 4 sur la plateforme de benchmark LMArena, afin de maximiser son score et sa position au classement.
Un modèle expérimental, calibré pour plaire
LMArena est un site communautaire où les modèles de langage s’affrontent dans des duels en tête-à-tête. Les visiteurs y soumettent une requête, comparent les réponses de deux modèles, et votent pour celle qu’ils jugent la meilleure. Un système de scores permet ensuite de classer les modèles selon leur popularité auprès des humains.
Parmi les prétendants, le modèle Llama-4-Maverick-03-26-Experimental de Meta s’est rapidement hissé à la deuxième place, juste derrière Gemini 2.5 Pro de Google.
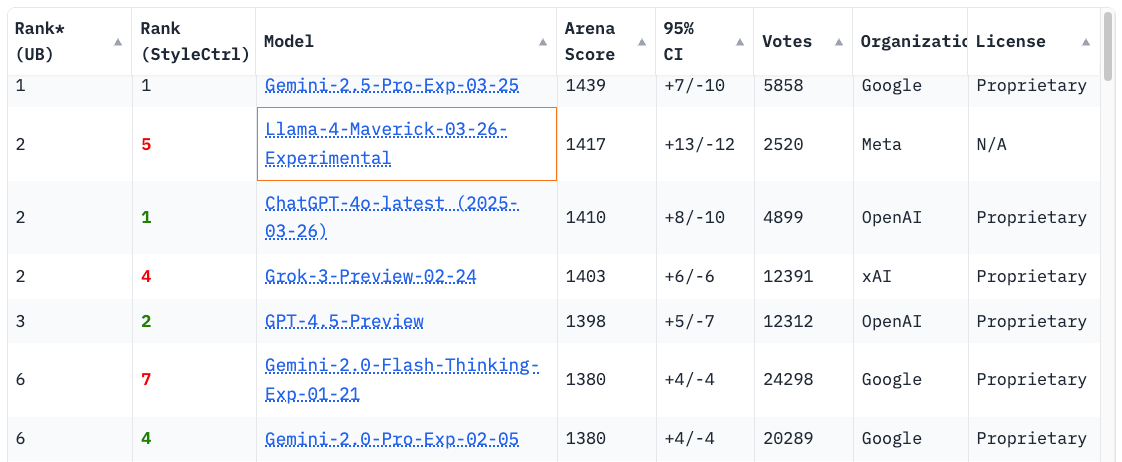
Seul problème : cette version expérimentale du modèle n'était pas disponible au public et semblait spécifiquement conçue pour exceller dans ce type de test — en particulier en ajustant son ton et son style de réponse pour séduire les votants.
Selon LMArena, les résultats montraient que cette version générait des réponses plus longues, plus engageantes, parfois agrémentées d’emojis, contrastant avec la version publique, bien plus concise et formelle. Ce tuning stylistique aurait donné à Meta un avantage injuste par rapport à ses concurrents, qui ont de leur côté soumis des modèles ouverts, disponibles à tous.
"Meta aurait dû être plus clair sur le fait que Llama-4-Maverick-03-26-Experimental était un modèle personnalisé, optimisé pour la préférence humaine", a déclaré LMArena dans un message publié hier :
We've seen questions from the community about the latest release of Llama-4 on Arena. To ensure full transparency, we're releasing 2,000+ head-to-head battle results for public review. This includes user prompts, model responses, and user preferences. (link in next tweet)
Early…
— lmarena.ai (formerly lmsys.org) (@lmarena_ai) April 8, 2025
Face à la polémique, LMArena a décidé de publier plus de 2 000 duels de modèles avec les requêtes (prompts), les réponses, et les préférences exprimées par les utilisateurs.
La plateforme affirme également avoir modifié ses règles pour mieux encadrer les soumissions et éviter que ce type de confusion ne se reproduise à l'avenir : "l’interprétation des règles par Meta ne correspondait pas à ce que nous attendons des fournisseurs de modèles" précise-t-elle.
Un upload de la version publique — comprenez "non expérimentale" — de Llama 4 Maverick depuis Hugging Face vers LMArena est également prévu, afin de fournir une base de comparaison plus transparente.
Meta assume, mais ne s'excuse pas

Meta, de son côté, ne nie rien. La société reconnaît avoir soumis une version expérimentale optimisée pour le dialogue, mais insiste sur sa "démarche exploratoire".
Un porte-parole a confirmé : "Llama-4-Maverick-03-26-Experimental est une version optimisée pour la conversation que nous avons testée et qui s’est bien comportée sur LMArena."
Dans le billet d'annonce du lancement de Llama 4 sur son blog officiel, Meta mentionne d’ailleurs cette version et son score de 1417 sur LMArena, sans expliciter qu’il s’agissait d’une mouture différente de celle publiée publiquement.
Mais de nombreux observateurs, y compris des chercheurs en IA, ont estimé que la distinction n'était pas claire, créant un fossé entre les performances annoncées et celles constatées par les utilisateurs une fois le modèle disponible.
À la guerre comme à la guerre
L’affaire est d’autant plus sensible que Llama 4 Maverick est présenté comme un concurrent sérieux aux modèles fermés d’OpenAI, Anthropic et Google.
Meta affirme que Maverick surpasse GPT-4o et Gemini 2.0 Flash sur de nombreux benchmarks. Mais cette annonce a rapidement été entachée par ces soupçons d’optimisation biaisée.
Ahmad Al-Dahle, responsable de Meta GenAI, a tenté de justifier les écarts de performance en évoquant une variabilité selon les plateformes ou services utilisés pour exécuter le modèle, encore en cours de stabilisation. Il a également nié toute accusation de triche sur les jeux de test.
Cette controverse intervient alors que Meta fait aussi parler sur le terrain de la neutralité politique de ses modèles.
La société assure que Llama 4 serait désormais moins biaisé, plus ouvert à une diversité de points de vue, et qu’il refuse moins souvent de répondre à des sujets sensibles. Un revirement stratégique assumé, qui s’accompagne de nouveaux efforts de test en sécurité (notamment via son programme GOAT, pour "Generative Offensive Agent Testing").
Les modèles Llama 4 sont disponibles sur Hugging Face en open source, bien que cette appellation soit contestée par l’Open Source Initiative, qui a déjà pointé des restrictions pour les utilisateurs européens.
À propos de l'auteur

Nicolas Lecointre
Chief Happiness Officer des développeurs, ceinture noire de sudo. Pour rire, j'ai créé Les Joies du Code. J'utilise Vim depuis 10 ans parce que je sais pas comment le quitter.
À lire également

Ma phobie administrative a enfin trouvé son fix, et il s’appelle Abby
Je DÉTESTE, je HAIS l'administratif. Voilà, c'est dit, et ça me semble être une belle entrée en matière pour cet article. C’est assez simple, à mon niveau, tout ce qui...
Articles similaires

OpenAI dévoile GPT-4.1 : son modèle IA nouvelle génération pensé pour les développeurs

Ce site fait s’affronter des IA pour créer des modèles Minecraft

OpenAI ouvre l'accès à o1-pro, son modèle d'IA le plus puissant et coûteux pour les développeurs

OpenAI dévoile Codex, son agent IA dédié au développement logiciel
OpenAI dévoile GPT-4.1 : son modèle IA nouvelle génération pensé pour les développeurs
Ce site fait s’affronter des IA pour créer des modèles Minecraft
OpenAI ouvre l'accès à o1-pro, son modèle d'IA le plus puissant et coûteux pour les développeurs
OpenAI dévoile Codex, son agent IA dédié au développement logiciel
Plus de contenu

Quand le sysadmin redémarre sans prévenir la machine sur laquelle on était en train de travailler

Quand je passe un script non testé en production

Et puis quoi encore ?

Quand on fait tester une nouvelle fonctionnalité au client

Quand le commercial se pointe en réunion plénière et récolte tous les lauriers pour ses projets

Quand ChatGPT me génère un énorme bloc de code qui correspond exactement à ce que j'attends

Quand je débugue mon code

Quand le dev senior vient nous aider pour corriger un bug
Quand le sysadmin redémarre sans prévenir la machine sur laquelle on était en train de travailler
Quand je passe un script non testé en production
Et puis quoi encore ?
Quand on fait tester une nouvelle fonctionnalité au client
Quand le commercial se pointe en réunion plénière et récolte tous les lauriers pour ses projets