Claude Opus 4.7 vient de sortir : ce que le modèle change pour les développeurs

Même tarif, meilleur code ? — Deux mois après Opus 4.6, Anthropic remet le couvert avec la sortie officielle de son nouveau modèle Opus 4.7.
Même grille tarifaire que son prédécesseur (5 dollars par million de tokens en entrée, 25 par million en sortie), des progrès nets sur à peu près tous les benchmarks, et un focus revendiqué pour les développeurs : la programmation agentique, ces sessions où le modèle écrit et modifie du code en autonomie pendant des minutes voire des heures, sans main humaine sur le clavier.

Le modèle est disponible dès maintenant sur l'API (identifiant claude-opus-4-7), Claude.ai et ses produits, ainsi qu'Amazon Bedrock, Google Vertex AI et Microsoft Foundry.
Des benchmarks qui piquent les concurrents
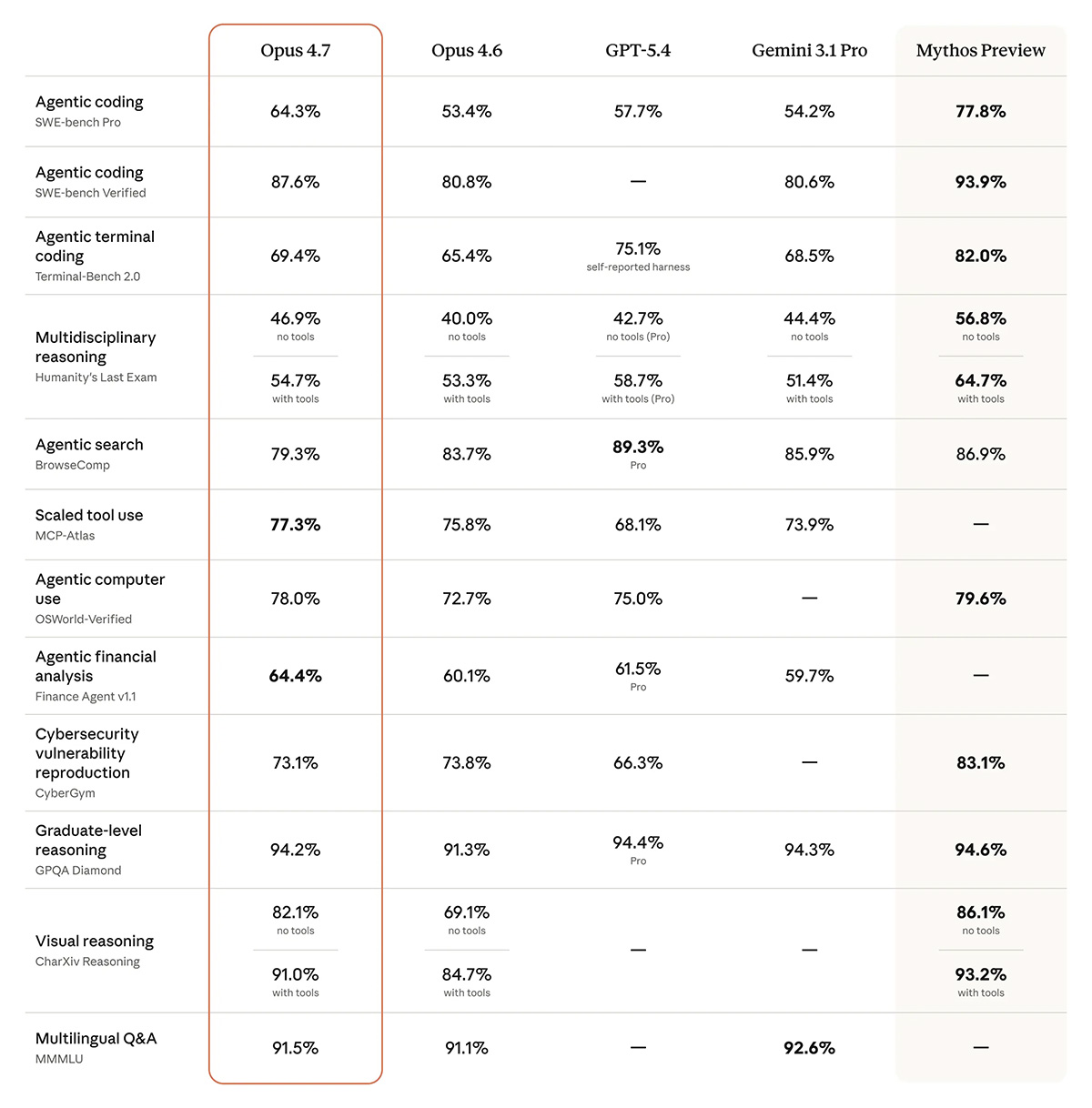
Sur le benchmark SWE-bench Pro, la référence pour les tâches de code longues et autonomes, Opus 4.7 grimpe à 64,3%, contre 53,4% pour Opus 4.6.
À titre de comparaison, GPT-5.4 plafonne actuellement à 57,7% et Gemini 3.1 Pro à 54,2%.
Même constat sur SWE-bench Verified (87,6% contre 80,8%) et sur CursorBench, où l'on passe de 58% à 70%, un saut rare pour ce qui reste, sur le papier, une mise à jour mineure.
Les chiffres partagés par les testeurs early-access sont dans la même veine : Rakuten rapporte trois fois plus de tâches de production résolues sur son benchmark interne. Notion voit ses workflows multi-étapes gagner 14% avec un tiers des erreurs d'outil en moins.
Et XBOW, qui fait des tests de pénétration autonomes en mode computer use (Claude pilote en direct sur la machine, clics et lecture d'écran compris), annoncerait un bond de 54,5% à 98,5% sur sa précision visuelle. Pour un agent qui doit lire des captures d'écran denses sans flancher, ça change pas mal la donne.
Carrément trop high
Si vous ne passez plus une seule journée sans vous passer de votre nouveau bro Claude Code, il y a des nouveautés au-delà du modèle.
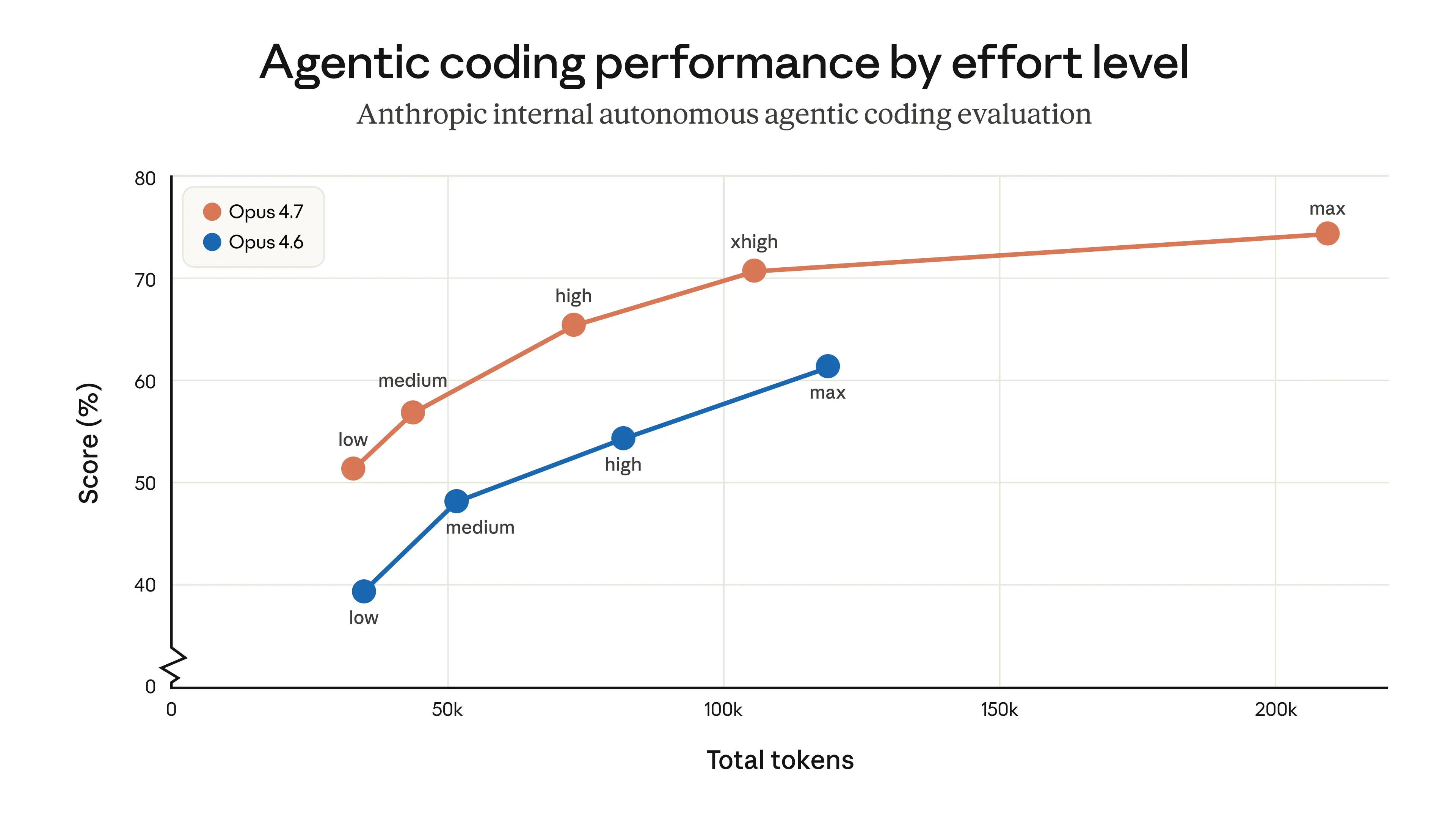
Un nouveau niveau d'effort xhigh s'intercale entre high et max, et devient le niveau d'effort par défaut dans Claude Code sur tous les plans.
La commande /ultrareview fait son apparition : une session dédiée qui relit le diff et remonte les bugs ainsi que les choix de conception qu'un reviewer attentif repérerait. Trois utilisations gratuites sont offertes aux abonnés Pro et Max pour tester.
L'auto mode, où Claude tranche lui-même sur les permissions en version plus "safe" que --dangerously-skip-permissions, est étendu aux users Max.
Enfin, les images en entrée acceptent désormais 2 576 pixels sur le plus grand côté, soit plus de trois fois la résolution précédente. Utile pour les captures denses, les schémas techniques et les agents en computer use qui lisent l'écran.
Le tokenizer fait monter le compteur
Anthropic le précise noir sur blanc dans ses notes de migration : le nouveau tokenizer peut faire gonfler l'input de 1 à 1,35× selon le type de contenu.
Aux niveaux d'effort élevés, Opus 4.7 réfléchit aussi plus longtemps avant de répondre, ce qui gonfle mécaniquement le volume de tokens en sortie. Le prix par token ne bouge pas, le nombre de tokens par prompt, si.
Un détail qui peut avoir son importance si vous êtes en production avec des intégrations calibrées pour 4.6.

Autre alerte glissée par Anthropic : le respect des consignes a fait un bond notable, ce qui veut dire que le modèle pourrait désormais prendre les prompts au pied de la lettre.
Les agents construits pour Opus 4.6, qui tablaient avant sur un modèle capable de zapper gentiment certaines consignes ambiguës, pourraient produire des résultats inattendus. Préparez-vous à re-tuner vos prompts.
Les garde-fous cyber au banc d'essai
Opus 4.7 sert aussi de terrain d'essai à une nouvelle salve de garde-fous cyber.
Mythos Preview (que l'on voit d'ailleurs apparaître sur les graphs des benchmarks partagés par Anthropic pour cette annonce) reste officiellement le modèle le plus capable de la maison — sa sortie publique est d'ailleurs gelée à cause de capacités cyber trop offensives.
Concrètement, des classificateurs automatiques scannent les prompts et bloquent ceux qui font penser à du red team non autorisé. Les pentesters et chercheurs en vulnérabilités, eux, peuvent demander une dérogation via le Cyber Verification Program pour lever ces blocages sur leurs comptes.
Pour le reste, Opus 4.7 affiche un profil d'alignement similaire à 4.6 : en léger mieux sur l'honnêteté et la résistance aux prompt injections, en léger moins sur les conseils trop détaillés autour de substances réglementées. 👀
Vous aimez lire ? Be my guest : le system card complet et ses 232 pages sont là pour qui veut plus de détails.
À propos de l'auteur

Nicolas Lecointre
Chief Happiness Officer des développeurs, ceinture noire de sudo. Pour rire, j'ai créé Les Joies du Code. J'utilise Vim depuis 10 ans parce que je sais pas comment le quitter.
À lire également

Ma phobie administrative a enfin trouvé son fix, et il s’appelle Abby
Je DÉTESTE, je HAIS l'administratif. Voilà, c'est dit, et ça me semble être une belle entrée en matière pour cet article. C’est assez simple, à mon niveau, tout ce qui...
Articles similaires

OpenAI lance ChatGPT Pro à 100$/mois pour les devs qui abusent de Codex

Meta lance Muse Spark et fait ses adieux à Llama (et à l'open source)

Anthropic laisse fuiter 512 000 lignes de Claude Code sur npm

Ollama passe à MLX : l'IA locale sur Mac passe la seconde
OpenAI lance ChatGPT Pro à 100$/mois pour les devs qui abusent de Codex
Meta lance Muse Spark et fait ses adieux à Llama (et à l'open source)
Anthropic laisse fuiter 512 000 lignes de Claude Code sur npm
Ollama passe à MLX : l'IA locale sur Mac passe la seconde
Plus de contenu

Quand quelqu'un me dit qu'il code en "C dièse"

Quand ça fait 2 jours de suite que je n'ai pas eu de bug dans mon code

Quand le chef m'apprend qu'on a remporté un nouveau projet avec une techno que j'adore

On est d'accord.

Quand je dois choisir entre une correction propre et un quickfix sale

Quand la démo ne se passe pas comme prévu

Quand le serveur répond 200 OK mais qu'absolument rien ne fonctionne

Quand on me demande un coup de main le vendredi soir
Quand quelqu'un me dit qu'il code en "C dièse"
Quand ça fait 2 jours de suite que je n'ai pas eu de bug dans mon code
Quand le chef m'apprend qu'on a remporté un nouveau projet avec une techno que j'adore
On est d'accord.
Quand je dois choisir entre une correction propre et un quickfix sale