GitHub va utiliser vos interactions avec Copilot pour entraîner ses modèles IA (vous pouvez dire non)
À partir du 24 avril, GitHub utilisera les inputs, outputs, snippets de code et le contexte associé de vos sessions Copilot pour entraîner et améliorer ses modèles d'IA.
Le changement concerne tous les utilisateurs des plans Free, Pro et Pro+, et il est activé par défaut. GitHub n'a prévu ni opt-in, ni pop-up de consentement, ni case à cocher. Si vous ne faites rien, vos données sont dans la machine.
Ce que GitHub veut (et ce que ça inclut)
L'annonce publiée sur le blog de GitHub détaille la liste de ce qui sera collecté. Et disons que la plateforme ne s’est pas fixé beaucoup de limites.
Concrètement, GitHub prévoit de collecter vos prompts, le code que vous montrez à Copilot, le contexte autour de votre curseur, la structure de vos repos, vos commentaires, votre documentation, et même vos réactions (pouces vers le haut ou vers le bas).
Bref, à peu près tout ce que vous faites avec Copilot.
La justification officielle ? L'incorporation de données d'interaction provenant d'employés Microsoft aurait déjà montré des améliorations significatives, notamment une augmentation du taux d'acceptation des suggestions dans plusieurs langages.
GitHub veut donc passer à l'échelle supérieure, en nourrissant ses modèles avec les interactions de ses 20 millions d'utilisateurs individuels.
Les repos privés, pas si privés que ça
GitHub le dit assez clairement dans sa FAQ, en choisissant ses mots avec précision : le contenu des repos privés n'est pas utilisé "at rest" (au repos), mais Copilot traite bien le code de vos repos privés quand vous utilisez activement l'outil.
Ces données d'interaction peuvent être utilisées pour l'entraînement, sauf si vous avez désactivé le réglage.
Le mot "privé" dans "dépôt privé GitHub" mériterait désormais un petit astérisque.
Les utilisateurs Copilot Business et Enterprise sont exemptés de cette collecte (leurs contrats l'interdisent), tout comme les étudiants et enseignants qui bénéficient d'un accès gratuit à Copilot.
Pour les utilisateurs individuels, la règle est simple : soit vous allez désactiver le réglage vous-même, soit vos données partent à l'entraînement.
Reste la question de la base légale en Europe, où le RGPD exige un consentement "libre, spécifique, éclairé et non ambigu”. Un opt-out activé par défaut semble difficilement cocher toutes ces cases.
On notera par ailleurs que les abonnés Pro, qui financent la plateforme de leur poche, sont précisément ceux qui seraient amenés à servir de carburant à cet entraînement.
Pour se justifier, GitHub pointe du doigt ses voisins : Anthropic, JetBrains et Microsoft (sa propre maison mère) ont des politiques d'opt-out similaires (oh, ben si tout le monde le fait alors, pourquoi pas nous ?).
Comment désactiver la collecte
Si vous préférez garder vos données pour vous, la manipulation est simple.
Rendez-vous dans vos paramètres GitHub Copilot en ligne, puis cherchez la rubrique "Privacy". Désactivez alors l'option "Allow GitHub to use my data for AI model training".
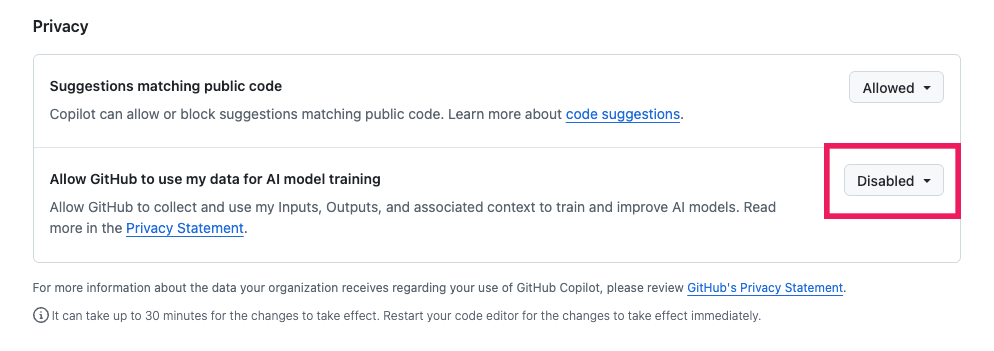
Bonne nouvelle : si vous aviez déjà désactivé le partage de données pour l'amélioration des produits par le passé, votre préférence a été conservée (vous n'avez rien à faire).
Autre précision utile : même si vous n'utilisez pas encore Copilot, vous pouvez désactiver ce réglage dès maintenant. Si vous activez Copilot un jour, votre préférence sera mémorisée.
Cela dit, rappelons que Codex, le modèle à la base de Copilot, a été entraîné sur du code public GitHub dès le départ, sans demander la permission à qui que ce soit.
À propos de l'auteur

Nicolas Lecointre
Chief Happiness Officer des développeurs, ceinture noire de sudo. Pour rire, j'ai créé Les Joies du Code. J'utilise Vim depuis 10 ans parce que je sais pas comment le quitter.
À lire également

Ma phobie administrative a enfin trouvé son fix, et il s’appelle Abby
Je DÉTESTE, je HAIS l'administratif. Voilà, c'est dit, et ça me semble être une belle entrée en matière pour cet article. C’est assez simple, à mon niveau, tout ce qui...
Articles similaires


Avec gh stack, GitHub veut vous aider à empiler vos pull requests proprement

VS Code passe aux releases hebdomadaires et introduit le mode Autopilot

Chat Control rejeté : le Parlement européen dit stop au scan de vos messages
Git City : vos commits GitHub intègrent une ville 3D en pixel art
Avec gh stack, GitHub veut vous aider à empiler vos pull requests proprement
VS Code passe aux releases hebdomadaires et introduit le mode Autopilot
Chat Control rejeté : le Parlement européen dit stop au scan de vos messages
Plus de contenu

Quand mes tests unitaires passent du premier coup

Quand on me demande de commencer à coder sans les specs

Quand je fais la démo d'une fonctionnalité un peu bancale

Quand je relis le code du stagiaire

Quand j'essaie d'implémenter un nouveau framework au talent, sans lire la doc

Quand quelqu'un fait une blague sur un langage que je ne connais pas

Quand je jette un œil au code source d'un projet de plus de 15 ans

Quand j'entends le commercial expliquer les différentes fonctionnalités au client
Quand mes tests unitaires passent du premier coup
Quand on me demande de commencer à coder sans les specs
Quand je fais la démo d'une fonctionnalité un peu bancale
Quand je relis le code du stagiaire
Quand j'essaie d'implémenter un nouveau framework au talent, sans lire la doc